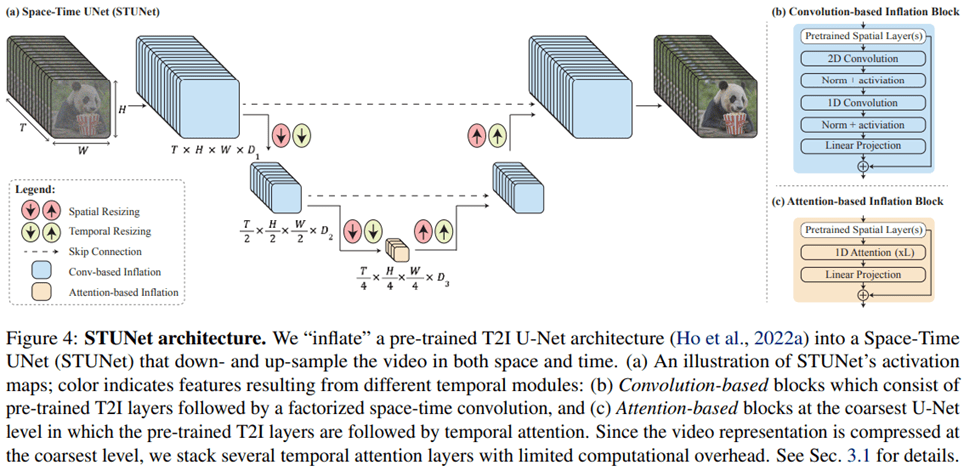
On January 23rd, 2024, Google announced their video generation model, Lumiere, with a preprint paper titled “Lumiere: A Space-Time Diffusion Model for Video Generation”. The model can do text-to-video generation, image-to-video generation, style-referenced generation, and video inpainting. Lumiere uses a space-time diffusion model based STUNet (Space-Time U-Net) architecture, which generates the whole temporal duration of video at once to maintain global temporal consistency, rather than synthesizing keyframes based on temporal super-resolution used by existing video models. The generative results from Lumiere in the paper demonstrated the high-quality and realistic generated videos and users’ preferences compared to the baselines. Lumiere is a latest AI tool for video generation, however, it can not be used for composing videos for multiple shots or making transiting between scenes. Also, the model is kept to Google’s own use, and no word regarding when the model will release to the public.

Resources:
Lumiere website: https://lumiere-video.github.io/
Demo video: https://youtu.be/wxLr02Dz2Sc
Preprint Paper: https://arxiv.org/pdf/2401.12945.pdf
